
Частой ошибкой при регрессионом анализе, которая встречается в работах студентов (чего греха таить, и аспирантов), является отсутствие графиков регрессии. Казалось бы, все посчитали, всем критериям удовлеворяет, чего еще надо. Ан, нет, не тут то было.
Квартет Энскомба
Для подтверждения это мысли рассмотрим такой курьезный пример, как “Квартет Энскомба” – специально подобранные в 1973 году данные английским математиком Ф. Дж. Энскомбом для иллюстрации важности применения графиков для статистического анализа, и влияния выбросов значений на свойства всего набора данных. Эти данные состоят из четырёх пар \(x\) и \(y\) с практически равным средним значением (\(M[x_i] = 9\), \(M[y_i] = 7.5\)) и дисперсией между соответствующими элементами пар (\(D[x_i] = 11\), \(D[y_i]\approx 4.13\)) , а также равным коэффициентом корреляции (\(cor(x_i,y_i) = 0.816\)). Модель линейной регрессии, построенная методом МНК для всех вариантов описывается уравнением \(y = 3.00 + 0.500x\). Графики представлены на рисунке ниже, из которого видно, насколько могут различаться данные, описываемые внешне статистически одинаково.
Код для построения графиков и графики приводятся ниже.
# Загружаем данные и выводим загруженную таблицу
load(url("https://tushavin.ru/RStudio/Ansc.Rda"))
knitr::kable(Ansc)| x1 | x2 | x3 | x4 | y1 | y2 | y3 | y4 |
|---|---|---|---|---|---|---|---|
| 10 | 10 | 10 | 8 | 8.04 | 9.14 | 7.46 | 6.58 |
| 8 | 8 | 8 | 8 | 6.95 | 8.14 | 6.77 | 5.76 |
| 13 | 13 | 13 | 8 | 7.58 | 8.74 | 12.74 | 7.71 |
| 9 | 9 | 9 | 8 | 8.81 | 8.77 | 7.11 | 8.84 |
| 11 | 11 | 11 | 8 | 8.33 | 9.26 | 7.81 | 8.47 |
| 14 | 14 | 14 | 8 | 9.96 | 8.10 | 8.84 | 7.04 |
| 6 | 6 | 6 | 8 | 7.24 | 6.13 | 6.08 | 5.25 |
| 4 | 4 | 4 | 19 | 4.26 | 3.10 | 5.39 | 12.50 |
| 12 | 12 | 12 | 8 | 10.84 | 9.13 | 8.15 | 5.56 |
| 7 | 7 | 7 | 8 | 4.82 | 7.26 | 6.42 | 7.91 |
| 5 | 5 | 5 | 8 | 5.68 | 4.74 | 5.73 | 6.89 |
Рассчитываем статистику
options(digits=3) # Устанавливаем вывод 3 знаков
apply(Ansc,2,mean) # считаем средние для колонок## x1 x2 x3 x4 y1 y2 y3 y4
## 9.0 9.0 9.0 9.0 7.5 7.5 7.5 7.5apply(Ansc,2,var) # считаем дисперсию колонок## x1 x2 x3 x4 y1 y2 y3 y4
## 11.00 11.00 11.00 11.00 4.13 4.13 4.12 4.12attach(Ansc) # Позволяет обращаться к колонкам по названию столбца
#считаем корелляцию между x и y для каждой пары
cat(cor(x1,y1),cor(x2,y2),cor(x3,y3),cor(x3,y3))## 0.816 0.816 0.816 0.816lm(y1~x1)##
## Call:
## lm(formula = y1 ~ x1)
##
## Coefficients:
## (Intercept) x1
## 3.0 0.5Выводим графики
# вывод 4 графиков на лист и смещение границ
# настройки сохраняем
oldpar<-par(mfrow=c(2,2),mar=c(4,4,1,1))
plot(y1~x1,xlab="X",ylab="Y",xlim=c(4,19),ylim=c(4,13),pch=19)
abline(a=3,b=0.5)
plot(y2~x2,xlab="X",ylab="Y",xlim=c(4,19),ylim=c(4,13),pch=19)
abline(a=3,b=0.5)
plot(y3~x3,xlab="X",ylab="Y",xlim=c(4,19),ylim=c(4,13),pch=19)
abline(a=3,b=0.5)
plot(y4~x4,xlab="X",ylab="Y",xlim=c(4,19),ylim=c(4,13),pch=19)
abline(a=3,b=0.5)
Построим регрессионные модели для каждого из четырех случаев
summary(lm(y1~x1)) # Первая пара##
## Call:
## lm(formula = y1 ~ x1)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.9213 -0.4558 -0.0414 0.7094 1.8388
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.000 1.125 2.67 0.0257 *
## x1 0.500 0.118 4.24 0.0022 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.24 on 9 degrees of freedom
## Multiple R-squared: 0.667, Adjusted R-squared: 0.629
## F-statistic: 18 on 1 and 9 DF, p-value: 0.00217summary(lm(y2~x2)) # Вторая пара##
## Call:
## lm(formula = y2 ~ x2)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.901 -0.761 0.129 0.949 1.269
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.001 1.125 2.67 0.0258 *
## x2 0.500 0.118 4.24 0.0022 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.24 on 9 degrees of freedom
## Multiple R-squared: 0.666, Adjusted R-squared: 0.629
## F-statistic: 18 on 1 and 9 DF, p-value: 0.00218summary(lm(y3~x3)) # Третья пара##
## Call:
## lm(formula = y3 ~ x3)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.159 -0.615 -0.230 0.154 3.241
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.002 1.124 2.67 0.0256 *
## x3 0.500 0.118 4.24 0.0022 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.24 on 9 degrees of freedom
## Multiple R-squared: 0.666, Adjusted R-squared: 0.629
## F-statistic: 18 on 1 and 9 DF, p-value: 0.00218summary(lm(y4~x4)) # Четвертая пара##
## Call:
## lm(formula = y4 ~ x4)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.751 -0.831 0.000 0.809 1.839
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.002 1.124 2.67 0.0256 *
## x4 0.500 0.118 4.24 0.0022 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.24 on 9 degrees of freedom
## Multiple R-squared: 0.667, Adjusted R-squared: 0.63
## F-statistic: 18 on 1 and 9 DF, p-value: 0.00216Обратимся к моделям. Все четыре примера проходят по критерию Фишера, коэффициенты значимы, коэффициент детерминации везде 0,67, однако на графиках видно, что нормальная регрессия у нас только в первом случае.
Во втором случае у нас явно квадратичная зависимость, а в третьем и четвертом помахи (выбросы) влияют на уровнение регрессии и при их удалении результат будет совершенно другой.
par(oldpar) # возвращаем сохраненные настройки
options(digits=7) # Значение по умолчанию
detach(Ansc) # Отсоединяем имена таблиц
rm(Ansc) # Удаляем таблицу из памятиКоэффициент корреляции и графики регрессии
Как вы должны помнить, для модели парной линейной регрессии коэффициент детерминации \(R^2\) равен квадрату обычного коэффициента корреляции между y и x.
Напоминаю, что коэффициент корреляции, сокращенно r, — это число от -1 до 1, которое отражает силу линейной связи между двумя числовыми переменными. Например, допустим, вы опросили 30 человек об их весе и росте и изобразили эти 30 пар (вес, рост) на диаграмме рассеяния.
Если все 30 точек данных идеально ложатся на возрастающую линию, то корреляция между этими двумя переменными будет равна r = 1.
Если же общая форма зависимости (вес, рост) возрастающая, но 30 точек данных не идеально ложатся на одну линию, то r будет где-то между 0 и 1; чем ближе точки данных к прямой линии, тем ближе к 1 будет r.
Если зависимость убывающая, то r будет лежать между 0 и -1, а если линейная зависимость между весом и ростом вообще отсутствует, r будет равен 0.
Один коэффициент корреляции может отражать любое количество закономерностей. Коэффициенты корреляции популярны среди исследователей, поскольку они позволяют обобщить взаимосвязь между двумя переменными в одном числе. Однако данный коэффициент корреляции может отражать любое количество закономерностей между двумя переменными, и без дополнительной информации (в идеале в виде диаграммы рассеяния), как видно из предыдущего примера, понять ее невозможно.
Чтобы проиллюстрировать это, Яном Ванховым (Jan Vanhove) была написана функция R, plot_r(), которая принимает на вход коэффициент корреляции и размер выборки и выводит 16 совершенно разных диаграмм рассеяния, которые все характеризуются одним и тем же коэффициентом корреляции.
Для пояснения графиков используется материал указанного автора «What data patterns can lie behind a correlation coefficient?«.
Коэффициент корреляции равен 0.5 (r=0.5)
Построим такие графики с коэффициентом корреляции 0.5 и размером выборки 35.
# Для установки пакета используете две строки ниже без #
# library(devtools)
# install_github("janhove/cannonball")
library(cannonball)
plot_r(r = 0.5, n = 35)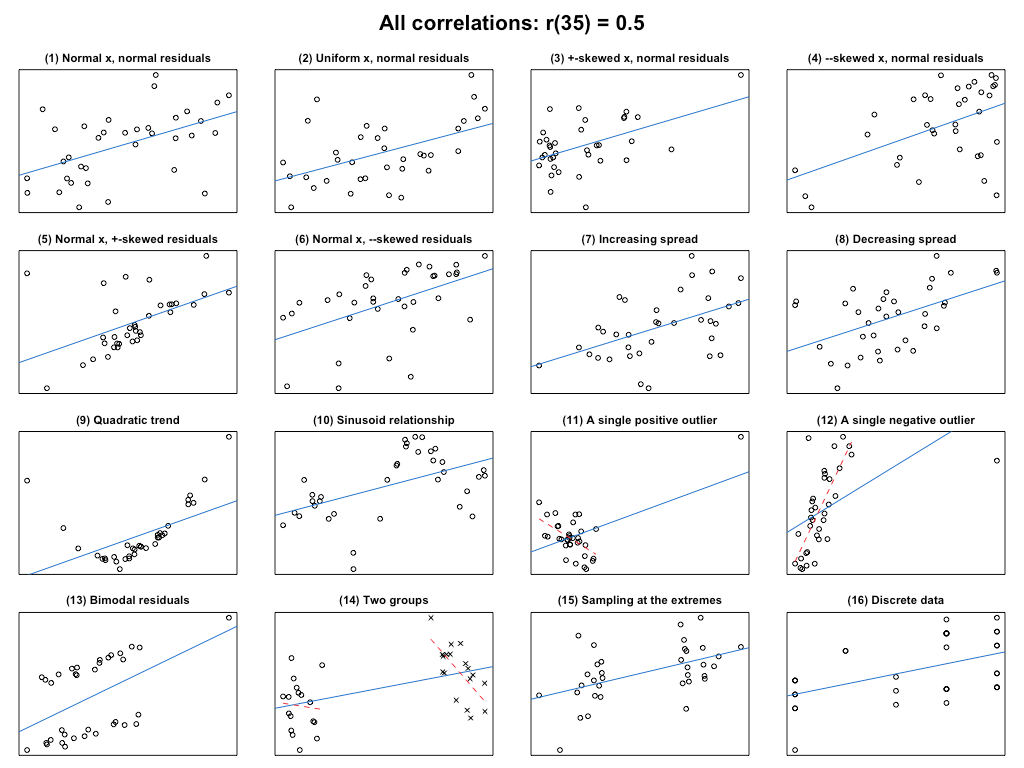
Верхний ряд
Обычно, что когда студенты думают о взаимосвязи с коэффициентом корреляции 0,5, они представляют себе что-то вроде графиков (1) и (2). На обоих графиках базовая зависимость между X и Y линейна, а значения Y нормально распределены относительно наилучшим образом подходящей прямой линии. Небольшое различие между (1) и (2) заключается в том, что для (1) X распределен нормально, а для (2) X распределен равномерно. Эти два графика отражают тот тип отношений, который должен был отразить r.
График (3) отличается от (1) и (2) тем, что переменная X теперь взята из смещенного распределения. В этом случае большинство значений X сравнительно малы, но одно значение X довольно велико. Такое распределение может быть, когда X представляет собой, например, результаты выполнения участниками трудного задания (эффект пола). В этом случае одно или несколько выходящих за рамки, но истинных значений X могут иметь (не будут иметь) “высокий рычаг”, то есть они могут неоправданно повлиять на коэффициент корреляции, вытянув его вверх или вниз.
Проблема в (4) похожа на проблему в (3), но теперь большинство значений X сравнительно большие, а несколько — довольно низкие, возможно, потому что X отражает выполнение участниками задания, которое было для них слишком легким (эффект потолка). Здесь также аутсайдеры могут иметь “высокий рычаг”, т.е. они могут чрезмерно влиять на коэффициент корреляции, так что он не будет точно характеризовать основную часть данных.
Второй ряд
Графики (5) и (6) представляют собой вариации на ту же тему, что и графики (3) и (4): Значения Y не распределены нормально относительно линии регрессии, а смещены. В таких случаях некоторые отклоняющиеся, но истинные значения Y могут (не обязательно) иметь “высокий рычаг”, т.е. они могут тянуть коэффициент корреляции вверх или вниз гораздо сильнее, чем обычные точки данных.
Графики (7) и (8) — это два примера, когда изменчивость значений Y относительно прямой линии увеличивается и уменьшается, соответственно, по мере увеличения X, хотя, конечно, в данном примере это не очень понятно. Это явление известно как гетероскедастичность. Основные проблемы со слепым полаганием на коэффициенты корреляции в присутствии гетероскедастичности, на мой взгляд, заключаются в том, что (а) “r = 0,5” одновременно занижает то, насколько хорошо Y можно оценить по X для низких (высоких) значений X, и завышает то, насколько хорошо Y можно оценить по X для высоких (низких) значений X, и (б) просто сообщая коэффициент корреляции, вы упускаете важный аспект данных. Кроме того, гетероскедастичность может повлиять на вашу инференциальную статистику (инференциальная статистика — это отрасль статистики, которая делает выводы о соответствующей популяции из набора данных, полученных из выборки, подвергнутой случайным, наблюдательным и выборочным вариациям. Как правило, результаты получают из случайной выборки населения, а выводы, полученные из выборки, затем обобщают для представления всей совокупности).
Третий ряд
График (9) иллюстрирует, что коэффициенты корреляции выражают силу линейной связи между двумя переменными. Если связь не линейная, то они малоинформативны. В данном случае r = 0,5 сильно занижает силу связи XY, которая оказывается нелинейной (в данном случае квадратичной). То же самое относится и к (10), где r = 0,5 занижает силу связи XY и упускает из виду циклический характер связи.
Графики (11) и (12) иллюстрируют, как единственная помеха, например, из-за технической ошибки, может дать вводящие в заблуждение коэффициенты корреляции. В (11) однин выброс данных дает сильную положительную корреляцию; если бы учитывались только данные слева, наблюдалась бы отрицательная связь (пунктирная красная линия). Слепое использование r = 0,5 неверно характеризует большую часть данных. В (12) зависимость значительно сильнее, чем r = 0,5 для основной массы данных (пунктирная красная линия); выброс снижает коэффициент корреляции. Графики (11) и (12) отличаются от графиков (3) и (4) тем, что в графиках (3) и (4) все значения X были взяты из одного и того же, но смещенного распределения и, как таковые, являются настоящими точками данных; в графиках (11) и (12) выбросы были вызваны механизмом, отличным от других точек данных (например, ошибкой кодирования или техническим сбоем).
Четвертый ряд
В (13) значения Y распределены бимодально относительно линии регрессии. Это говорит о том, что мы упустили из виду какой-то важный аспект данных, например, фактор группировки: возможно, точки данных выше линии регрессии были отобраны из другой популяции, чем точки ниже линии регрессии.
Ситуация на графике (14) похожа на ситуацию в (13), но значительно хуже ее: Набор данных содержит две группы, но в отличие от (13), общая тенденция, отражаемая r = 0,5, скрывает тот факт, что внутри каждой из этих групп связь XY на самом деле отрицательная. График (14) часто, но не всегда, дает такую картину, которая известна как парадокс Симпсона.
На графике (15) показана ситуация, когда исследователи, вместо того чтобы изучать взаимосвязь XY по всему диапазону X, изучали только случаи с самыми экстремальными значениями X. Выборка по крайним значениям завышает коэффициенты корреляции (см. причину № 2, по которой я не очень люблю коэффициенты корреляции). Другими словами, если вы возьмете выборку из 150 случаев XY и посмотрите только на 50 самых экстремальных значений X, вы получите коэффициент корреляции, который с большой вероятностью будет больше, чем тот, который вы наблюдали бы, если бы рассмотрели все 150 случаев.
Наконец, график (16) — это то, что на самом деле представляют собой многие коэффициенты корреляции. Например, данные X и Y неровные, потому что они представляют собой данные подсчета или ответы на вопросы анкеты. Не факт, что коэффициенты корреляции для таких моделей сами по себе обманчивы, но мы явно говорим о другой модели, чем на графиках (1) и (2).
А если коэффициент корреляции равен нулю (r=0)?
plot_r(r = 0, n = 35)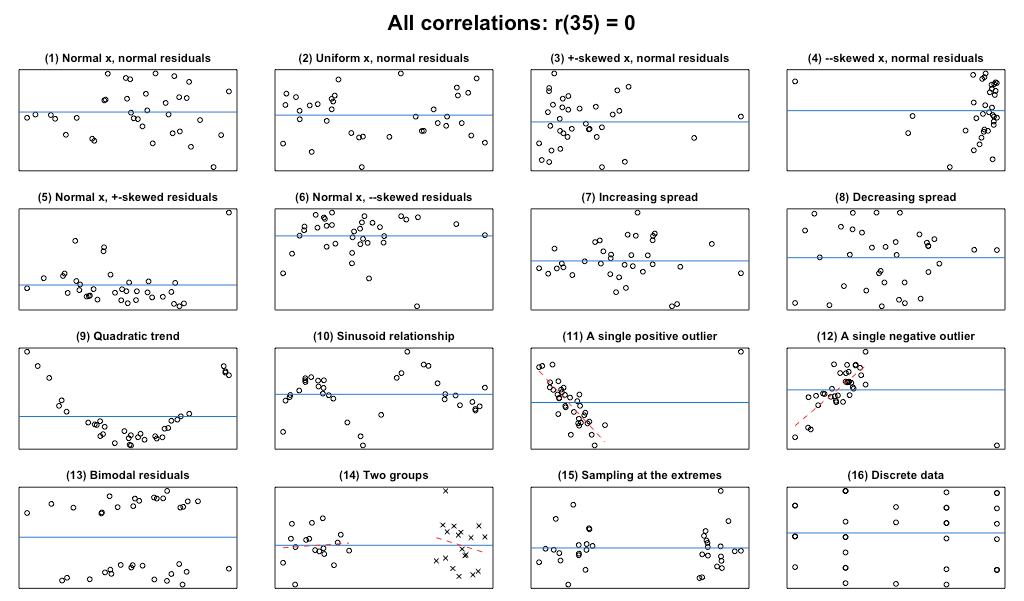
Главное, что видно из этих графиков, это то, что r = 0 не обязательно означает отсутствие связи XY. Это ясно из графиков (9) и (10), которые демонстрируют сильную нелинейную зависимость. Графики (11) и (12) также подчеркивают этот момент: Существует сильная взаимосвязь для большей части данных, но эта тенденция аннулируется одной точкой данных. Иногда, как показано на графике (14), тенденция, присутствующая в двух подгруппах, может быть не видна в агрегированном анализе; однако в данном примере это не так.
А если коэффициент корреляции равен 0,75 (r=0,75)?
Как мы помним, коэффициент детерминации для модели с константой принимает значения от 0 до 1. Чем ближе значение коэффициента к 1, тем сильнее зависимость. При оценке регрессионных моделей это интерпретируется как соответствие модели данным. Для приемлемых моделей предполагается, что коэффициент детерминации должен быть хотя бы не меньше 50 % (в этом случае коэффициент множественной корреляции превышает по модулю 70 %).
Посмотрим на такие графики
plot_r(r = 0.75, n = 35)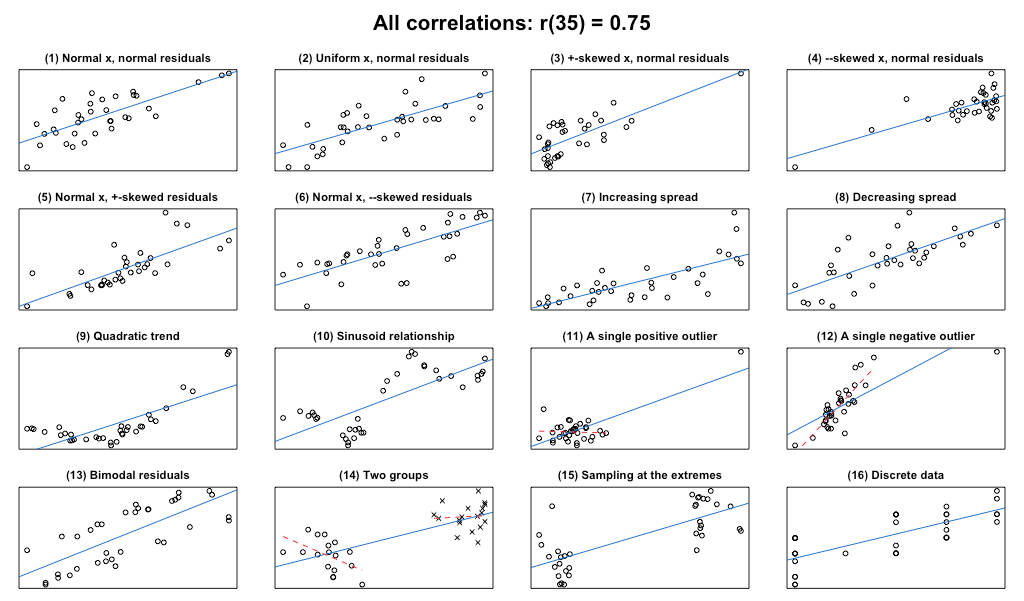
Комментарии, надеюсь, излишни. Пояснения к рисунку аналогичны пояснениям к первому примеру с r=0.5